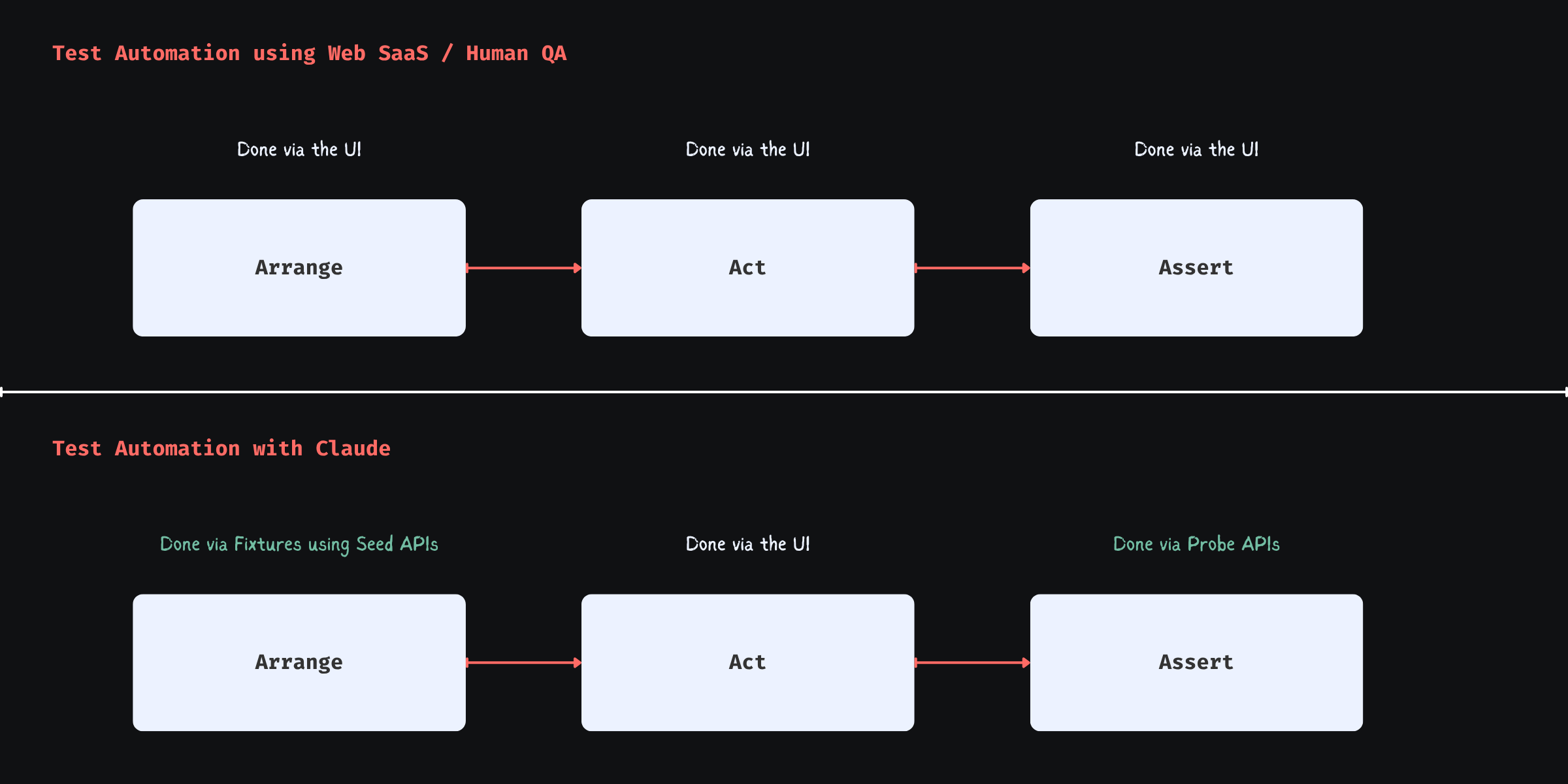
Boiling the lake - QA style


Garry Tan recently introduced a simple but powerful idea: The old adage “don’t boil the ocean” is bad advice in the AI agent era. Well - at the very least, “lakes” are now very much “boilable”.
The core insight is: AI compresses certain work by orders of magnitude. That doesn’t just make things faster - it fundamentally changes what’s feasible.
Most people ask the wrong question:
“What existing human workflows can we speed up with AI?”
That’s incremental thinking. The real leverage comes from asking:
“What powerful workflows did we avoid entirely because they were too expensive to do with humans?”
Those are your “lakes”. And with AI, many of them go from infeasible → trivial.
The QA lake
In QA - making “test authoring faster” is akin to the former. The bigger ROI lies in the granular workflows that get unlocked now that agents can take autonomy in your test automation.
The Big Idea:
Could agents execute a workflow - where they continuously monitor “planned reality” (user stories / scenarios) and “production reality” (real user behaviour patterns) to improve the “tested reality” (test suite + test infra) - in a continuous feedback loop. All of it done in the background - looping you in for approval of plans it makes.
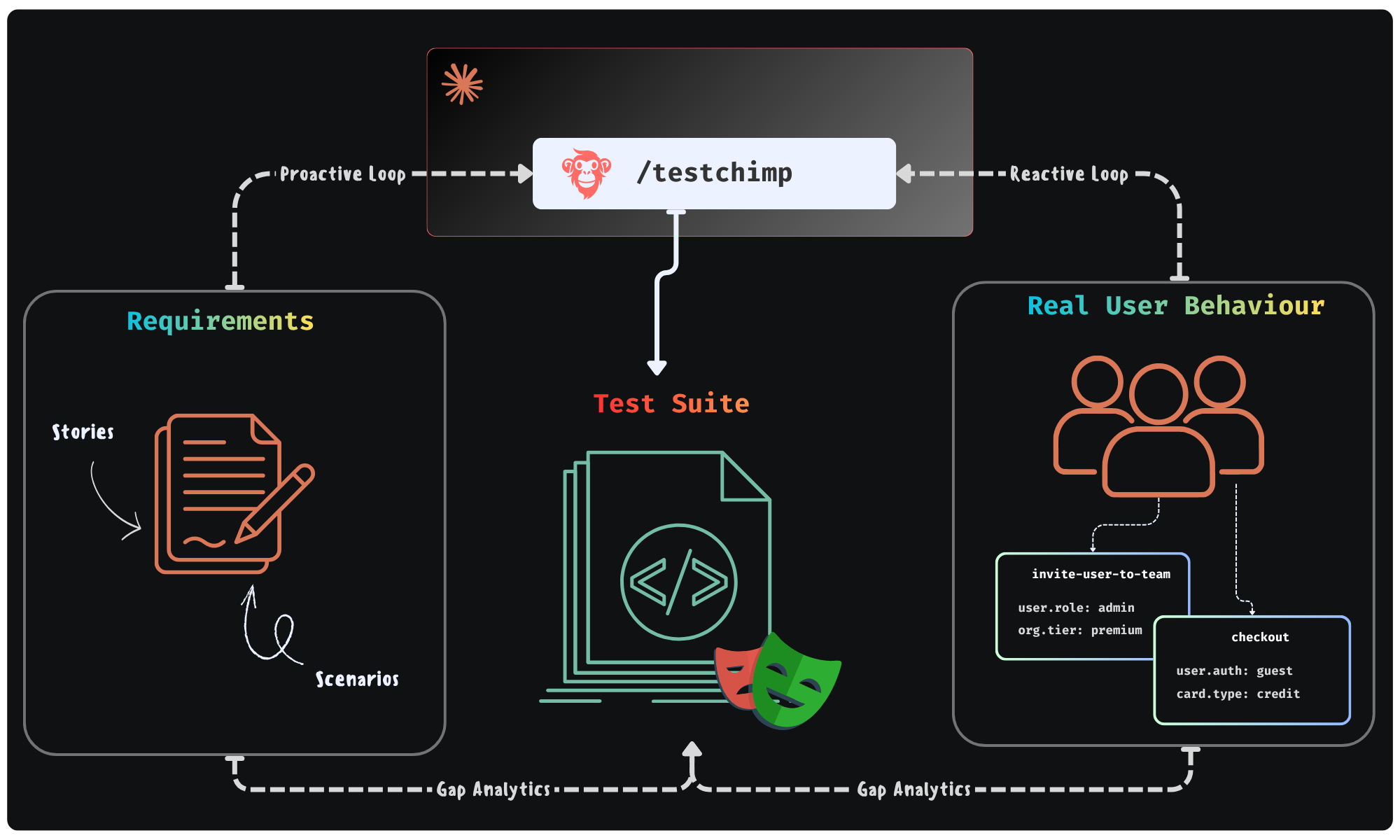
This is exactly the future we were building TestChimp for - where agents participate in each phase of QA; where agents access real world insights / plan artifacts to self-direct its work strategically.
Claude + TestChimp
Today, we are adding the final piece of the puzzle: A SKILL that you can install on Claude / Cursor that enables just that.
- In TestChimp, test plans are already maintained as Markdowns in repo - directly accessible to agents.
- Requirements are linked to tests via in-code comments - that Agents can author.
- Test executions are auto-tracked by our Playwright plugin
- Event ingests are tracked across prod and test - to generate TrueCoverage insights.
The Skill “upskills” Claude to read those insights via our CLI / MCP, to plan and execute the entire QA workflow:
- Understand coverage gaps, prioritize (using signals exposed by TestChimp) and plan
- Author fixtures that emulate real-world situations observed
- Update test infrastructure (seed / probe endpoints) as needed
- Author tests - (provisioning PR-local envs to test in and validating tests work)
- Update instrumentations to learn about real user behaviour (for future cycles - covering new user journeys introduced)
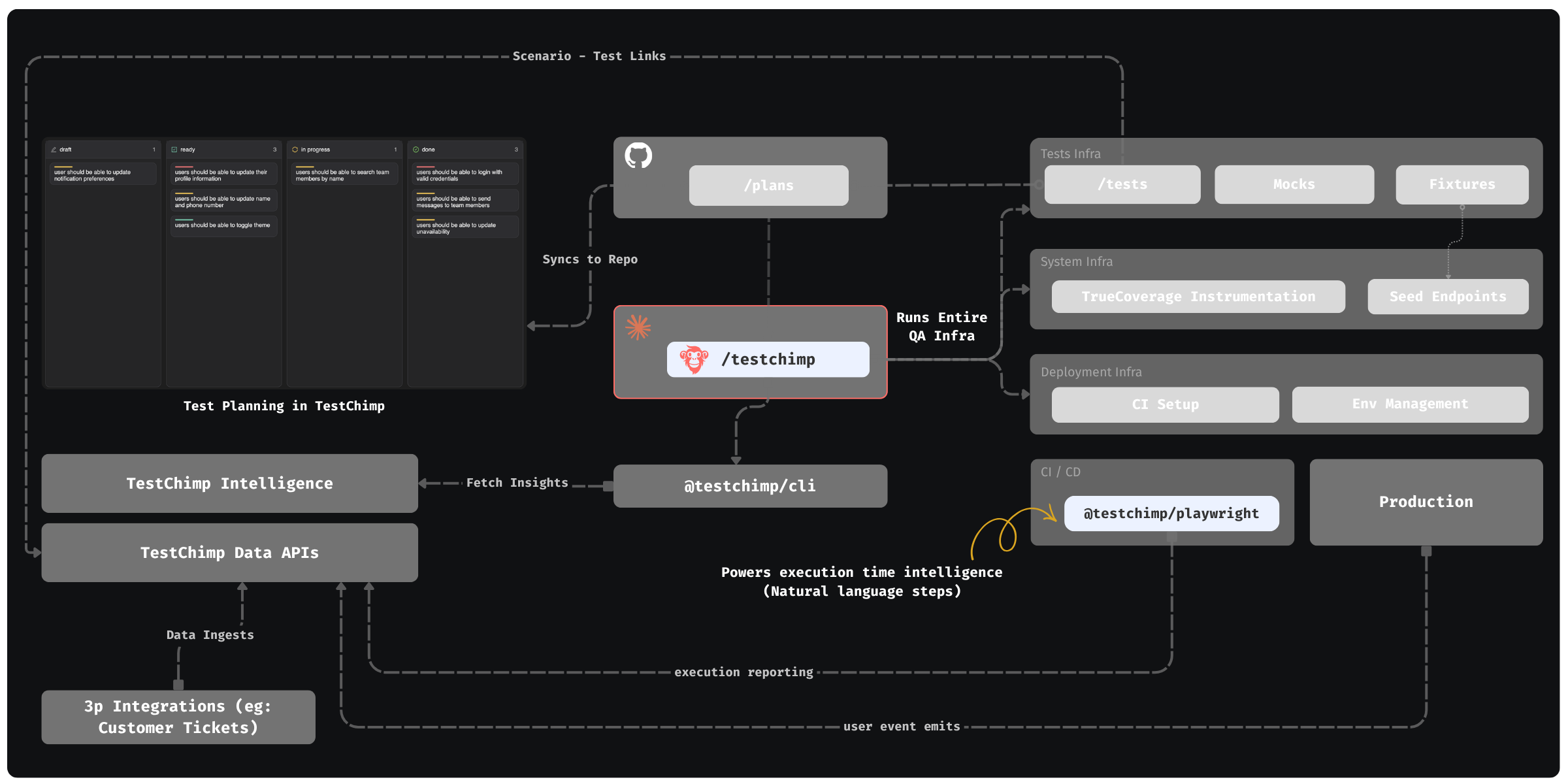
The best part: All of this is condensed to just 2 commands - enabling a frictionless DevX:
-
/testchimp test-> (Run after each PR) Updates plans, authors seeds / fixtures, author tests, validate them in PR scoped isolated environments, instrument code for TrueCoverage -
/testchimp evolve-> (Run periodically / on deploy) Audits test coverage aligned with requirements and real-user insights, to “evolve” your QA infra & test suite to cover critical under-tested areas and do corrective actions & run targeted exploratory runs.
Claude can write tests. With the right feedback loop, it can fully manage an effective, self-evolving QA posture that de-risks your product continuously. This is what TestChimp enables, by making each phase of QA agent-native, informed by requirements and real user behaviour insights, in a tight feedback loop.